从公历年底拖到了农历年底,还是要杂七杂八写点东西。
技术
以后的职业生涯,还是得做技术。
Fun
可能有些矫情,但是还是要感慨一下:“职业生涯能跟技术(信息技术)强相关真的太有趣了”。原因么?可能更加矫情——完美符合“唯物主义世界观”。
计算机——在不考虑量子计算机一夜之间突然普及的情况下——也就是冯诺依曼机,是个建立在确定性之上的玩意儿:电流通过晶体管,不是 0 就是 1;按一下键盘按键,就是会在操作系统层面产生一个中断;公司给你银行账户打了 100 的工资,到账金额很难大于 100 块。一个再复杂的软件系统,在忽略一些条件——比如硬件故障(随手搜了下,2019 年主流硬盘一年也就不到 2%的故障率)、软件 bug 的条件下,给定一个确定的收入,必然有一个确定的输出。比如 google 搜索,应该是地球上最大最复杂的几个 codebase 之一了,但是在足够熟悉背景知识和代码的前提下,给定一个关键词,你总是有办法预测返回的 html。而另一些复杂的“系统”,就根本无法预测,比如明天的 A 股指数。
为了保证确定性,复杂性则无法避免(能力有限,无法做形式上的证明),而解决复杂性,就是这门行当的乐趣所在了。这种乐趣,可以类比于解决了数学试卷上最后一道大题的智力上的满足感,如果你 get 不到这种满足感,多半也不适合于理工科的工作了。就拿我比较熟悉的互联网/游戏领域来说,复杂性的问题们由来已久、司空见惯,前端要解决负责状态与 UI 的同步问题;后端要解决单台计算机算力不足的问题;游戏就是要在苛刻的的条件下渲染出让人满意的画面。面对这些问题,不断有个人/公司/甚至是一堆相互完全不认识只是信奉开源的个人(真有宗教的气味)提出各种各样的解决方案,持之以恒、孜孜不倦。而在熟悉和膜拜了各种解决方案以后,能够自己提出一个哪怕是再微小再袖珍的解决方案,也足以让人神清气爽。这还只是技术的层面,再结合产品、运营等等,一个项目的复杂性更是比“最后一道大题”还会要大,如果能解,则喜不胜收。
科&技
某个 podcast 听来的——中国自古不缺技术,只是缺科学。这一理论在现而今的 IT 领域又一次得到了验证:应用层面 BAT 市值巨大、基础层面(硬件、操作系统)差距巨大。考虑历史进程,这一现状也不是不能理解,毕竟西方抢跑了几十年。不过只要政策有倾斜,上层足够重视,我相信依靠我大社会主义先进性,差距还是能缩小甚至反超的。只是让人看不懂的是,都 9012 年了,还有借着微内核国产编译器疯狂营销的(我也相信还是有强行给大家一点信心的因素的)、还有 python 套个皮装木兰的(这个就纯粹是在贡献段子了)、做区块链躲到海南去还要上交超级密钥的。只能说荀子说得对,性本恶。
拔得有点太高了,说回个人层面,当个程序员,还是很能体会到科学和技术之间的碰撞的。其他领域不了解,但我觉得高级一线工人需要偶尔读个一两篇 paper 的工种不会很多,而程序员就是其中一个。做游戏的,读点 SIGGRAPH 正常吧;做大数据的,google 的 BigTable 那几篇应该怎么也扫过;都不做,为了赶上潮流,比特币的“圣经”总也还是撇过一两眼的。
赶上了科技革命的浪潮,计算机领域从科学到技术的转化简直是前所未有的快。youtube 看了个视频,某 AI 领域做 deep learning 的专家,在大家都不看好的情况下,坚持研究,终于赶上了 AI 浪潮,一朝翻身成为学术权威,下狗逆袭,可歌可泣。我专门注意了一下老专家入行的时间——80 年代初,满打满算也就 40 年不到,AI 也就从实验室走出来,走到每个人的身边了。40 年就等来了大规模应用,隔壁 20 世纪初诞生的高能物理啥的,羡慕到哭呀。
环境这么友好,程序员怎么能不“两手都要抓,两手都要硬”呢?
科学硬!动态规划的面试题不会做,总得知道O(n*log(n))好过O(n^2)吧;白板上写不出来二叉树反转,看看 wiki 电脑上总是写得出来吧;rax和eax分不清(正是在下,mac 上写了个 helloworld 老是 link 不过,结果抄的是 32 位的汇编),branch prediction 也该晓得一二。别说“这有啥用”“反正又用不到”,用处可大了!往大了说:人类这个族群就是靠些“没啥用”的研究进步的(市井的角度讲,古希腊研究天文有啥用?);往小了说:本来生活就很“贫瘠”了,总不能连好奇心都丢了吧。
技术硬!能明白好的工程都是妥协,都是 tradeoff,不去钻牛角尖,晓得 premature optimazation 不但是 evil 也是成本的浪费。每一个方案,从 why 到 how 都很重要。太阳底下没有新鲜事,从这个项目到另一个项目,从这段代码到那段代码,可以是 copy->paste,也可以是 copy->learn->paste,更可以是 copy->study->learn->write。
两手都硬的程序员,才是个好的“纺织女工”,才算得上是“计算机基础扎实”。
语言
rust
自己三番五次的想要入坑 rust,终于找到点时间看完了一遍 tutorial,学习曲线是挺陡的。主观感受 rust 的定位还是很明确的——需要做 native 甚至是 system level 开发,但是嫌 C“原始”,又嫌 C++“复杂”(内存管理的复杂)的场景。borrow checker 这东西比 objective-c 的 auto release 成熟多了、也合理多了,下次有需要 native 的场合,一定要试下 rust。关于额外收获,在某个 rust 的 talk 里有这样一张图,图片来自 youtube 截图:
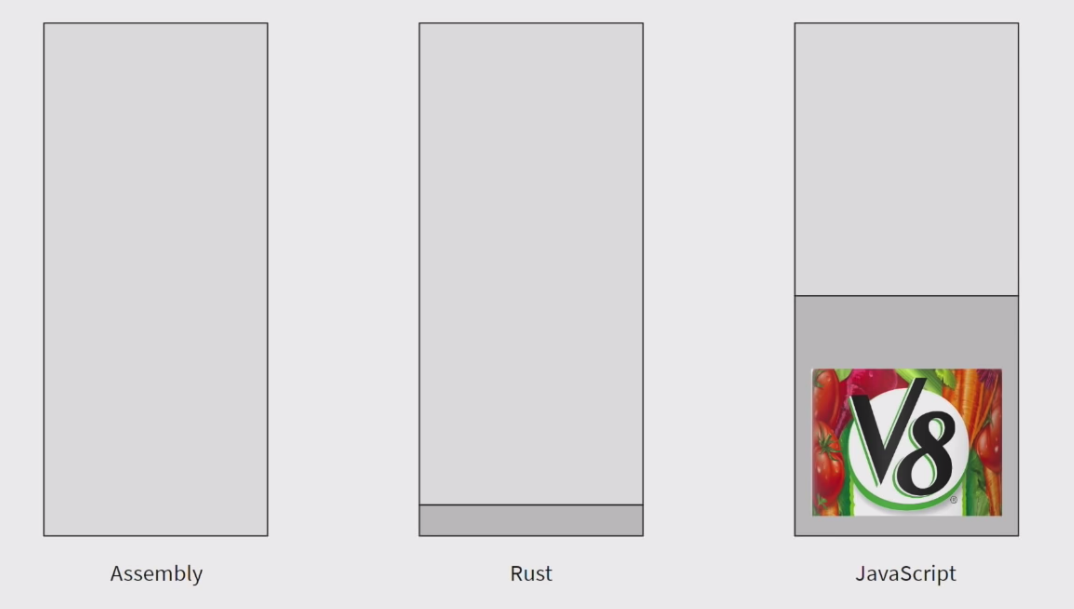
这个对 runtime 的图示真的挺有启发性的,管你是 native 编译还是有 VM,从进程内存的角度来看都有依赖。并不是说 native 不需要装些 runtime 就没依赖了,只是依赖多少罢了,少的依赖个 libc,多的依赖个 v8。反正你的进程里总还是有别人写的代码,就算是汇编,进程里都还是有 kernel 的代码呀(针对宏内核)。VM 听起来又是 GC 又是 JIT 的,说白了就是有人帮你写了很多代码(不管有用没用、好不好用,你都的用)。写代码的基础就是站在前人的肩膀上。
thinkPHP
php 用过,这次是必须要改点用了 thinkPHP 这个框架的代码,也就顺便看了下这个框架。看了下来,只有实名 diss 这一种态度,并不因为是国货而有任何偏袒。知乎上有理有据的 diss 挺多,我只说一点:一个框架,官网上全是广告我理解,都要恰饭,但是为啥文档里只有 how,根本没有 why。设计思路啥的完全不谈,advanced topic 根本没有,全都是“如果你需要 X 功能,那就 copyY 代码就可以了”。这是真把人往码农上带啊。这是中国最流行的框架之一,可怕。
开源
吹爆开源!再感慨一次,这个时代的程序员是何其幸运,在任何领域,想要学习工业上最成熟的解决方案,也就是在 github 上“冲冲浪”的事情。
前段时间搜我自己的邮箱,偶然看到两个邮件:一个是我原来翻译过 ruby 的官方网站中的某个页面;二是发邮件问某库作者一个实现的问题,人家洋洋洒洒给我解释了一大堆。单独看起来没什么值得大惊小怪的,但这两个邮件都是 2013 年的事了,也就是在我开始职业生涯不到 3 年的时间里发生的,可以想象对一个“初级程序员”来说,这都是多么大的鼓励。感谢国际友人,感谢开源。
Merkle Tree
震惊,一个数据结构支撑了世界上 80%的程序员的日常工作,还值千亿美元?!!
嗯,merkle tree,因为比特币的大火成了“网红”数据结构,图片来自 wiki:
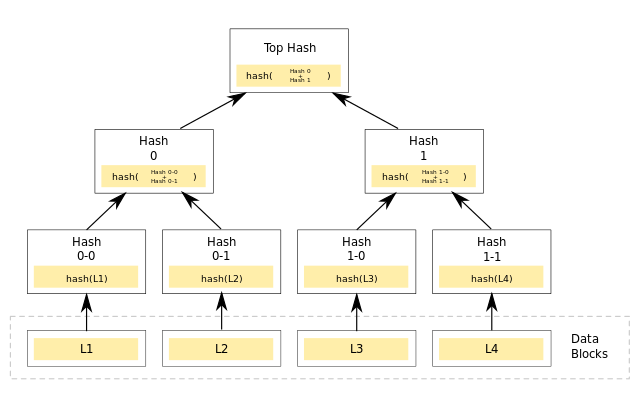
说简单点就是一颗二叉树,只用来记录 meta 信息,叶子节点记录真实的数据块的 hash,其他节点记录两个子节点的 hash 值拼接后的 hash(parent = hash(left ++ right))。这个数据结构应用非常广:bt 下载校对文件、比特币在一个节点里记录 tx、git 里的 tree hash(严格来说不是 merkle tree,因为不是二叉树,是个多叉树)。这个数据结构核心就是:易容定位差异!如果一个数据块发生了变化(bt 下错了一段文件、比特币篡改了一笔 tx、git 里修改了一个文件),那么对应节点的所有祖先节点都会连带发生变化,那么从 root 开始对比,也很容易找到最终是哪一个或那几个数据块发生了变化(最后重新下载错的文件块、deny 掉篡改、checkout 的时候只还原出对应文件即可)。
似乎 bt 下载的历史上,还出现过一个更简单的数据结构:还是切分数据块,每块算 hash,然后把每个 hash 相连算一个总 hash(finalHash = hash(hash0 ++ hash1 ++ …. hashN)),没有树形结构。跟 merkle tree 相比似乎也能很快的对比出文件在总体上有没有变化,但是无法定位到底是哪一个数据块发生了变化,出错的时候只有重新全部重新下载一次了(从 99.99%重新变成 0%,似乎我也经历过)。
总的来说,就是一个“看过参考答案会直呼原来如此”就忘不掉的实用数据结构。
管理
管理的方法论比较欠缺,都是一些身体力行之后的浅显经验(又称土法炼钢),说起来就三点:
- 建立制度:用互联网产品方法论的角度来讲就是——人都喜欢确定性。比起隔三差五临时发版,管他大小每周一个版本就是有效率;就算两分钟完事,每天定时一个早会也会让人更有团队的感觉。巴普洛夫训狗、老大哥管人、谎话说一万次就是真的,褒贬不论,重复就是能达成目标,这是生物本性。
- 完善沟通:人不是机器,很多现代的工作也不是光靠螺丝钉就能完成的,“发挥主观能动性”发挥你一个人没用,要尽量发挥所有人的。怎么发挥呢?有一个很“等于没说”但又很准确的答案:具体问题具体分析。但问题是啥,还是要沟通了才知道啊,所以沟通是一切的前提。
- 明确目标:这个东西才是长期来看最重要的,毕竟“人定胜天”,天天开会、一对一随时沟通也不能让你带队爬雪山过草地,“坚信必将解放全人类”才能。没那么大的目标咋办?目标不在大小,都相信就行。每个人的目标都不一样咋办?这个好说,有个很容易定的目标——说加薪就加薪,毕竟“一般等价物”,不就是拿来等价价值的吗。
技术管理
其实也没啥特别的,就是管理加上了技术的前缀。管理学从秒表加皮鞭进化而来,在需要创造性行业又渐渐失效。要怎么再次高效起来我不懂,毕竟不是研究管理学的,但我毕竟身处一个非常需要创造性的行业,还是有一些观察的。说简单点:就是将资源倾斜到有创造性的个体上(多给有创造性的人加薪、多招有创造性的新人)。那么要如何辨别“有创造性”的个体?没有一定的标准,但我觉得拿“有创造性”的必要条件来衡量一定没错——那就是“有学习能力”。不会的主动学、会的主动举一反三,学习能力还是比较容易辨识的。